EvidentialMix
Learning with Combined Open-set and Closed-set Noisy Labels
Background
Deep learning has achieved impressive results on problems that seemed insurmountable, if not impossible, not too long ago. Its growing applications in areas ranging from computer vision and natural language processing to bio-informatics and medical imaging has made it a very captivating tool for industry and academics alike. However, much of the recent success of deep learning is largely attributed to supervised learning, where the efficacy of models depends on the availability of large-scale datasets with clean and reliable labels. Acquiring such large-scale datasets is typically very expensive and time-consuming, and the cheap alternatives often result in datasets that have noisy labels. Consequently, one of the important challenges of the field is the development of methods that can cope with such noisy datasets.
Types of label noise
Label noise can be broadly categorised into two categories: open-set noise and closed-set noise. A sample is said to have a(n):
- closed-set noisy label – when its true label is present in the known label set
- open-set noisey label – when its true label is (strictly) not in the known label set.
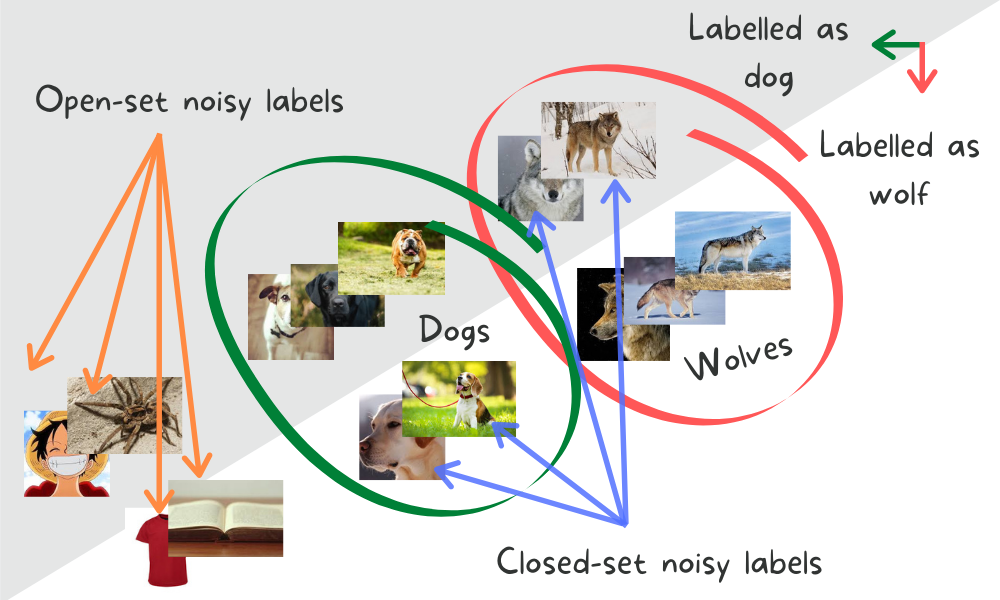
Traditionally, the study of closed-set and open-set noisy labels has been done in isolation from one another i.e. all the systematic studies (with controlled label noise) that have been presented, evaluated their methods on datasets that were exclusively corrupted with either closed-set noise or open-set noise. However, it is quite easy to argue that both open-set and closed-set noise are likely to co-occur in real-world data sets. Therefore, in this work, we formulate a novel benchmark evaluation to address the noisy label learning problem that consists of a combination of closed-set and open-set noise.
Prior works
The state-of-the-art approaches that aim to solve the closed-set noisy label problem focus on methods that identify the samples that were incorrectly annotated and update their labels with semi-supervised learning (SSL) approaches for the next training iteration. This strategy is likely to fail in the open-set problem because it assumes that there exists a correct class in the training labels for every training sample, which is not the case. On the other hand, the main approach addressing the open-set noise problem targets the identification of noisy samples to reduce their weights in the learning process. Such strategy is inefficient for closed-set problems because the closed-set noisy label samples are still very meaningful during the SSL stage.
Hence, to be robust in the scenarios where both closed-set and open-set noise samples are present, the learning algorithm must be able to identify the type of label noise affecting each training sample, and then either update the label, if it is closed-set noise, or reduce its weight, if it is open-set noise.
Contributions
The main contributions of this paper are the following:
- We formulate a novel benchmark evaluation for the noisy label learning problem that consists of a combination of open-set and closed-set noisy labels and propose a new learning algorithm, called EvidentialMix (EDM), to address it.
- We show that EDM is able to accurately distinguish between clean, open-set and closed-set samples, thus allowing it to exercise different learning mechanisms depending on the type of label noise. In comparison, previous methods can only separate clean samples from noisy ones, but not closed-noise from the open-noise samples.
- We show that our method can learn superior feature representations than previous methods as evident from the t-SNE plots below, where our method has a unique cluster for each of the known label/class and another separate cluster for open-set samples. In comparison, previous methods have shown to largely overfit the open-set samples and incorrectly cluster them to one of the known classes.
- We experimentally show that EDM produces classification accuracy that is comparable or better than the previous methods on various label noise rates.
Method
The main impediment when dealing with this combined problem is the need to identify closed-set and open-set noisy samples since they must be dealt differently by the method. We suggest to address this problem by associating closed-set samples with high losses computed from confident but incorrect classification, and open-set samples with uncertain classification. To achieve this, we propose the use of the subjective logic (SL) loss function
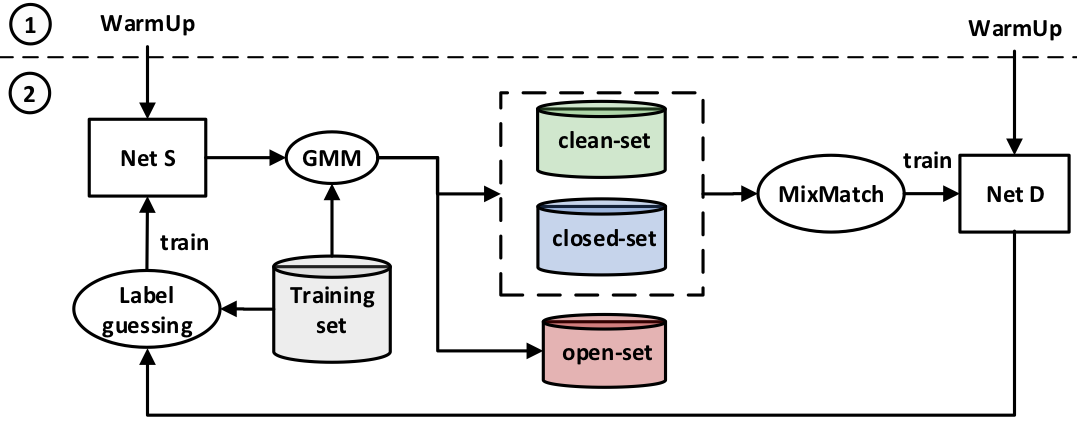
Our proposed method simultaneously trains two networks: NetS, which uses the SL loss; and NetD, which uses a SSL mechanism. Broadly speaking, the ability of the SL loss to estimate classification uncertainty allows NetS to divide the training set into clean-set, open-set and closed-set samples. The predicted clean-set and closed-set samples are then used to train NetD using MixMatch as outlined in
As NetS iteratively learns from the labels predicted by NetD, it gets better at splitting the data into the three sets. This is so because the labels from NetD become more accurate over the training process given that it is only trained on clean and closed-set samples, and never on predicted open-set samples. The two networks thus complement each other to produce accurate classification results for the combined closed-set and open-set noise problem.
Experiments
Following the prior works on closed-set and open-set noise problems
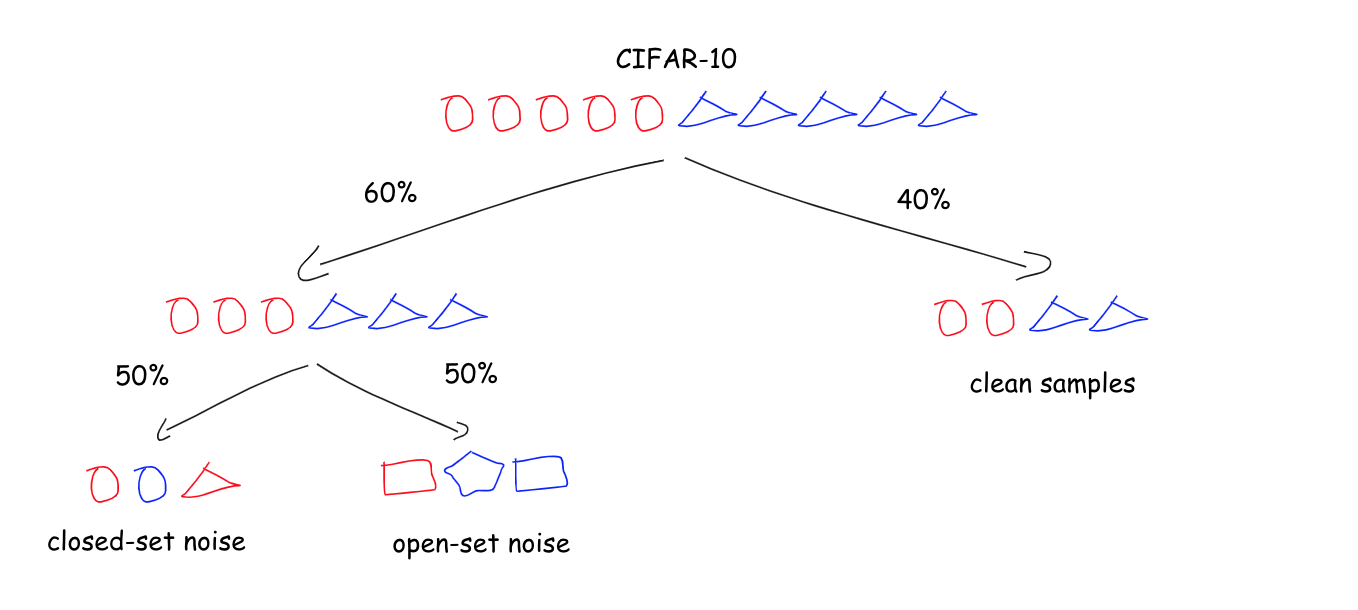
\(\rho \times 100\%\) of the CIFAR-10 images are selected at random (constituting the noisy samples), out of which –
- the labels of \(\omega \times 100\%\) samples are symmetrically shuffled (closed-set noise); and
- the images for the remaining \((1-\omega) \times 100\%\) samples are replaced with random images from CIFAR-100 or Imagenet-32 (open-set noise).
Results
We compare our approach with DivideMix
Classification accuracy
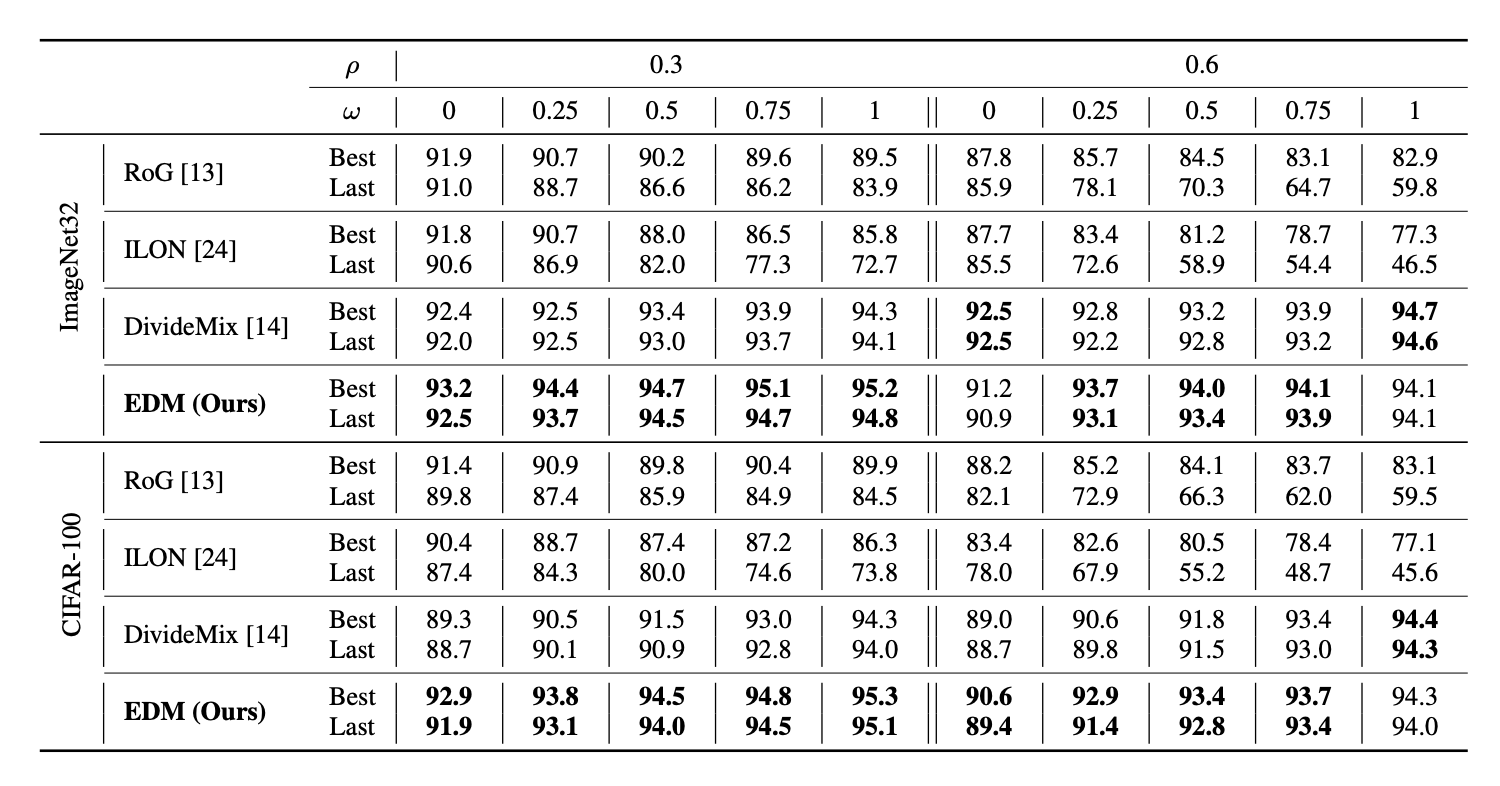
Results show that our method outperforms all the competing approaches for 17 out of the 20 noise settings and is a close second on the remaining 3.
Feature representations
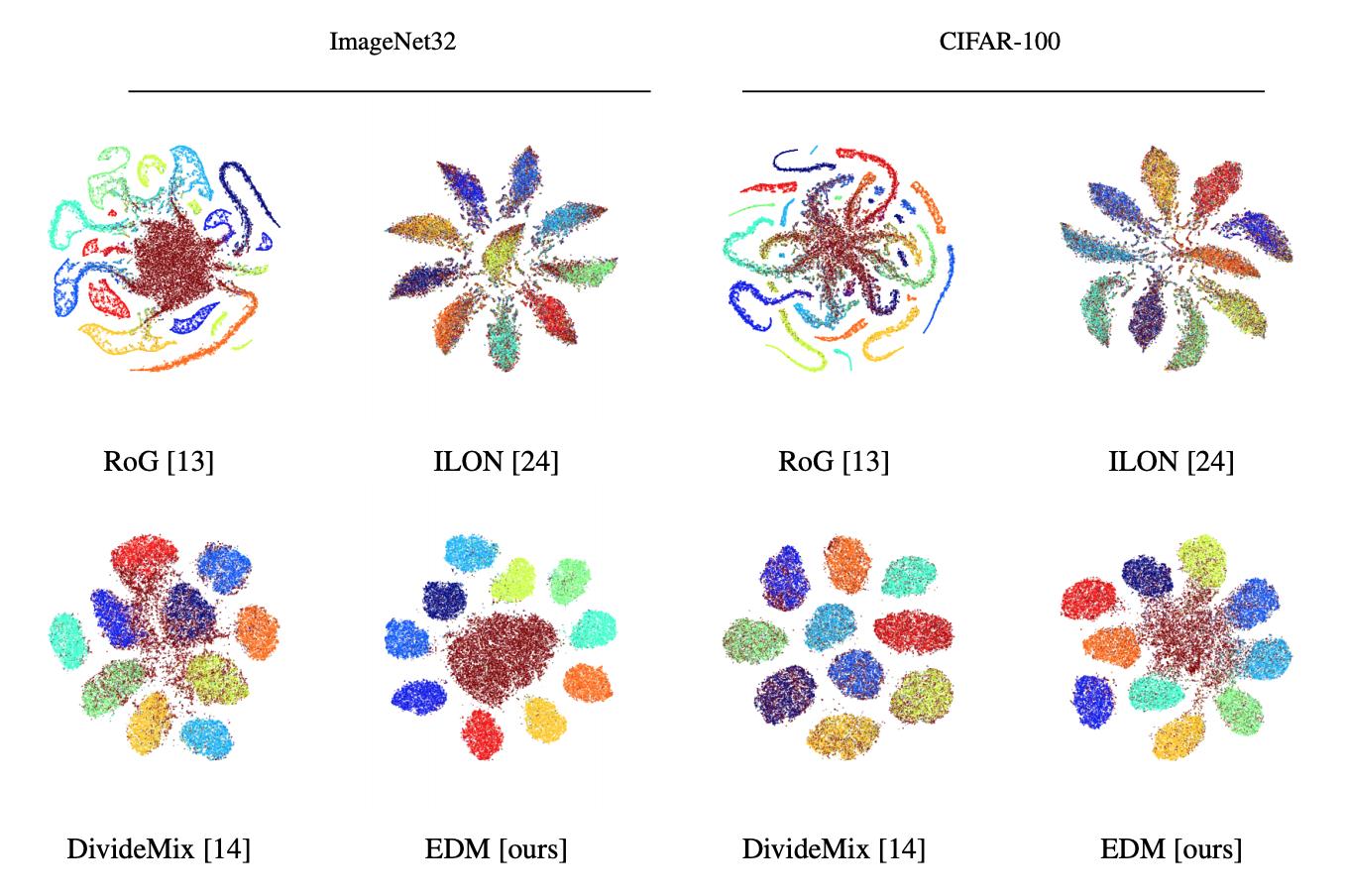
The t-SNE plots show that our proposed method is quite effective at separating open-set samples (brown) from the other clean and closed-set training samples, while DivideMix and ILON largely overfit these samples, as evident from the spread of brown samples around CIFAR-10 classes. Interestingly, RoG also shows a good separation, but with apparently more complex distributions than EDM.
Conclusion
The motivation for introducing this problem was to open the dialogue in the research community to investigate the combined open-set and closed-set label noise. In this work, we investigated a rather simple kind of label noise – symmetric label noise i.e. the process of introducing synthetic noise used a uniform random distribution. In real-life scenarios, however, that is not the case. Moving forward, we aim to explore more challenging noise settings such as incorporating asymmetric and semantic noise in the proposed combined label noise problem.
If you find this work useful, please considering citing us:
@InProceedings{Sachdeva_2021_WACV,
author = {Sachdeva, Ragav and Cordeiro, Filipe R. and Belagiannis, Vasileios and Reid, Ian and Carneiro, Gustavo},
title = {EvidentialMix: Learning With Combined Open-Set and Closed-Set Noisy Labels},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2021},
pages = {3607-3615},
}